Introduction
You now understand how diffusion generates images. A model starts with pure noise and, step by step, sculpts it into something coherent. You also know that this process happens in latent space — a compressed representation that makes the whole thing computationally possible. If those concepts are still fuzzy, it is worth revisiting Part 1 (diffusion) and Part 2 (latent space) before continuing.
But generating a video is a fundamentally different challenge. A video is not just a slideshow of independent images. Each frame needs to flow naturally from the one before it — a person mid-smile in frame 12 should be slightly more smiling in frame 13, not suddenly frowning or facing a different direction.
The core question behind image-to-video AI is deceptively simple: how do you make a diffusion model that understands time?
The Core Challenge: Temporal Coherence
Imagine you have a really good image diffusion model. You run it 24 times to produce 24 frames. Each individual frame looks great — sharp, realistic, well-composed. But when you play them back as a video, the result is unwatchable.
Objects teleport between frames. A person's face subtly changes shape from one frame to the next. The background shifts as if the camera is having a seizure. None of it looks like continuous motion.
Why? Because each frame was generated from different random noise, with absolutely no connection to its neighbors. Frame 5 has no idea that frame 4 exists. Each frame solved the problem of "generate a realistic image matching this description" independently, and independent solutions do not produce coherent sequences.
Think of it like a flipbook. If you ask 24 different artists to each draw one page of a flipbook based on the same description — "a cat jumping off a table" — you will get 24 perfectly good drawings of a cat jumping off a table. But when you flip through them, the cat will change size, the table will move, and the motion will be jarring. Now imagine one artist drawing all 24 pages, constantly referencing the previous and next pages. That is what a video model needs to do.
The technical term for this is temporal coherence — the property that adjacent frames are consistent with each other in a way that produces the illusion of smooth, continuous motion. Achieving temporal coherence is the central challenge that separates video generation from image generation. Video models must treat frames as a 3D volume, not separate 2D images. Naive independent generation produces jarring, incoherent motion.
Video models must treat frames as a 3D volume, not separate 2D images. Naive independent generation produces jarring, incoherent motion.
From 2D to 3D: Adding the Time Axis
In image diffusion, the model works with a 2D grid of values. Think of it as a rectangle: height by width. Every pixel (or every latent value, if we are in latent space) has a position on this flat grid. The model learns spatial relationships — how the top of an image relates to the bottom, how an eye relates to the nose next to it.
For video, we add a third axis: time. Instead of a flat rectangle, the model now works with a 3D block — height by width by frames. You can picture it as a stack of image frames, like a deck of cards, where each card is one frame and the deck's thickness represents the duration of the video.
The noise that the model starts from is no longer just a 2D sheet of static. It is a 3D volume of noise that spans both space and time. When the model denoises this volume, it is simultaneously shaping all frames at once. This is the key insight. The model does not generate frame 1, then frame 2, then frame 3 sequentially. It refines the entire video in parallel, step by step, just like an image model refines all pixels simultaneously.
Because the model processes all frames together, it naturally learns relationships between them. It learns that an object in the same spatial position across adjacent frames should look similar. It learns that motion should be smooth. It learns what should change (the position of a waving hand) and what should stay the same (the background behind it).
And because all of this happens in latent space (from the previous article), the 3D block is much smaller than the raw pixel volume. A 24-frame, 512x512 video in pixel space would be roughly 18 million values. In latent space, that might compress down to around 300,000 — making the computation feasible on current hardware. Image diffusion works on a flat 2D grid. Video diffusion adds a time axis, creating a 3D volume that the model denoises all at once.
Image diffusion works on a flat 2D grid. Video diffusion adds a time axis, creating a 3D volume that the model denoises all at once.
Temporal Attention: How Frames Talk to Each Other
Attention is one of those terms that sounds vague but has a very precise meaning in machine learning. It is a mechanism that lets different parts of the input influence each other during processing. When one part of the data "attends to" another part, it means the model is using information from that other part to help make decisions about the current part.
In image diffusion models, attention connects different spatial regions within a single image. When the model is generating the area around someone's mouth, it can "look at" the area around their eyes to make sure the expression is consistent. This is called spatial attention — attention within a single frame.
Video models introduce a second type: temporal attention. This lets each frame look at other frames. When the model is processing frame 5, it attends to frames 4 and 6 (and potentially frames further away) to understand what came before and what should come after. This is what creates smooth transitions. Every frame is generated while being fully aware of its neighbors.
Think of it this way. An animator drawing frame 5 of a sequence has frames 4 and 6 pinned up on the wall for reference. She constantly glances at them to make sure the motion flows correctly — that the arm she is drawing is in a position that makes sense between where it was (frame 4) and where it is going (frame 6). Temporal attention is the mathematical equivalent of those pinned-up reference frames.
In practice, video diffusion models alternate between these two types of attention throughout their architecture:
Spatial attention layers process each frame independently, building up understanding of how parts within a single frame relate to each other. Then temporal attention layers process across frames, connecting the same spatial positions across time. The model alternates back and forth — spatial, temporal, spatial, temporal — gradually building up both detailed per-frame understanding and smooth cross-frame coherence.
This alternating pattern is elegant because it decomposes a very hard problem (understanding a full 3D video volume) into two simpler sub-problems that the model tackles in turns. The spatial layers handle "what does this frame look like?" and the temporal layers handle "how does this frame connect to the ones around it?"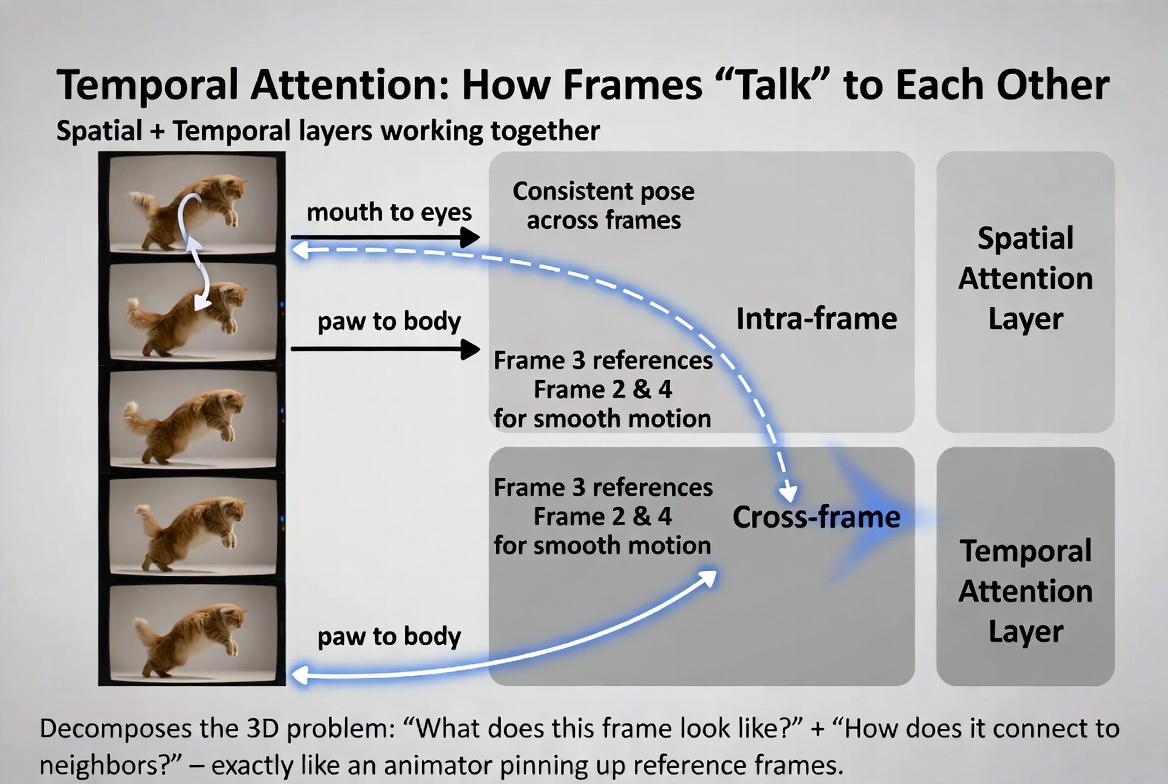 Temporal attention connects frames to each other (cross-frame), while spatial attention connects regions within a single frame (intra-frame).
Temporal attention connects frames to each other (cross-frame), while spatial attention connects regions within a single frame (intra-frame).
Image Conditioning: Your Photo as the Anchor
Everything we have discussed so far applies to video generation in general. But image-to-video has a special advantage: you provide a starting photo. This photo acts as an anchor that constrains the entire generation process.
Here is how it works. Your photo is first run through an encoder — the same type of encoder we discussed in the latent space article — which compresses it into a latent representation. This latent becomes the fixed first frame of the video. The model does not need to imagine what frame 1 looks like because you have already told it.
From there, the model generates motion that flows naturally from your image. It might initialize all subsequent frames from a noisy version of your photo's latent, or it might start with pure noise for frames 2 through 24 while keeping frame 1 fixed. Either way, the denoising process — with its temporal attention — ensures that every generated frame stays consistent with that anchor image.
This is fundamentally different from text-to-video, where the model must generate everything from scratch. In text-to-video, the model has to decide what the subject looks like, what the background is, what the lighting conditions are, what the composition is — all from a text description. That is an enormous space of possibilities.
With image-to-video, all of those decisions are already made. Your input photo nails down the subject's appearance, the background, the lighting, the color palette, and the composition. The only thing the model needs to figure out is motion — how things move from this starting point. That is a much more constrained problem, which is why image-to-video models generally produce more consistent, more realistic results than their text-to-video counterparts.
Think of it as the difference between asking someone to "paint a scene and then animate it" versus showing them a photo and saying "now make this move." The second task is dramatically easier because 90% of the creative decisions are already made.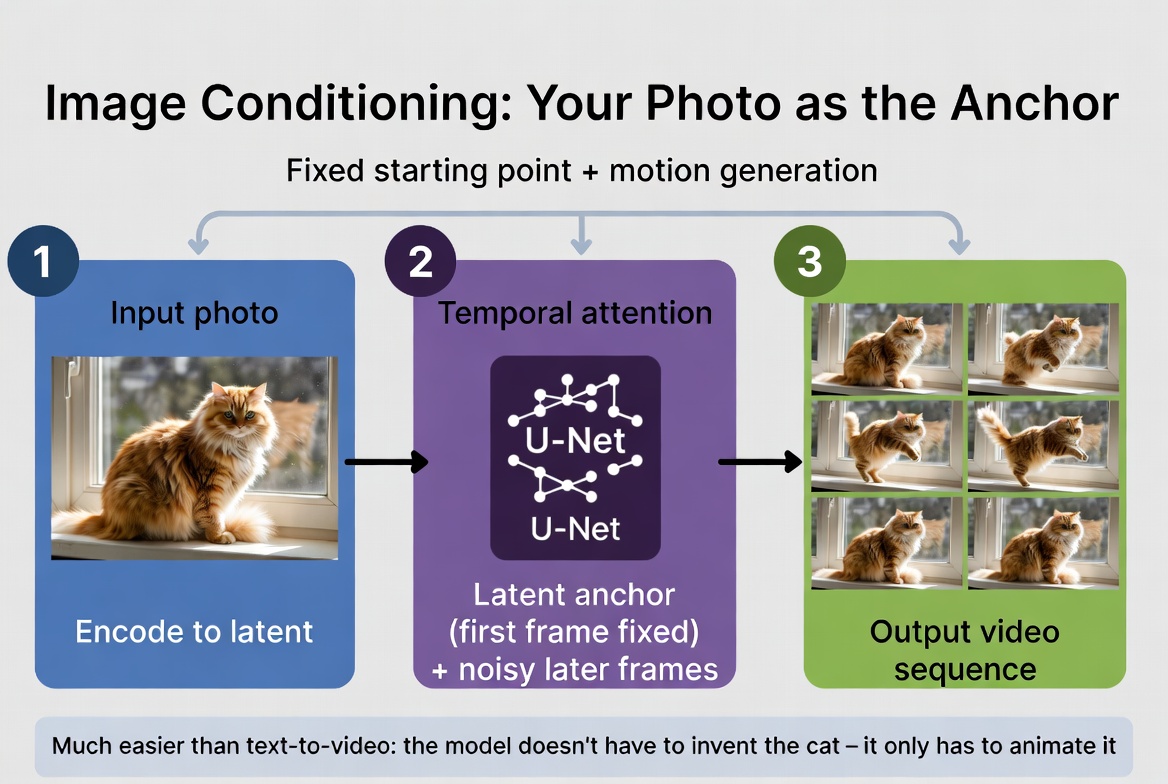 In image-to-video generation, your photo is encoded and anchors the first frame. The model only has to animate it, not invent it.
In image-to-video generation, your photo is encoded and anchors the first frame. The model only has to animate it, not invent it.
Text Conditioning and Classifier-Free Guidance
Besides your input image, most image-to-video models also accept a text prompt describing the desired motion. You might write "a gentle smile spreading across her face" or "wind blowing through the trees" to guide what kind of motion the model generates.
But how does text actually influence the generation process? This is where classifier-free guidance (CFG) comes in. It is one of those techniques that sounds complicated but has an intuitive core.
During each denoising step, the model actually generates two predictions. One prediction follows your text prompt. The other prediction ignores it entirely — as if no prompt was given. The model then compares these two predictions and amplifies the difference. The logic is: whatever is different between the "prompted" and "unprompted" versions must be what the prompt is contributing, so lean into that difference.
The strength of this amplification is controlled by a guidance scale. Higher values mean the output follows the prompt more aggressively. The motion will match what you described, but it might become exaggerated or unnatural. Lower values mean the model relies more on its own learned priors, producing more natural-looking motion that might not precisely match your instructions.
This is a slider, not a switch. Finding the right balance between prompt adherence and natural motion is part of the art of generation. In practice, most consumer-facing image-to-video tools (like Picto.Video) handle this automatically, choosing a guidance value that works well for most use cases. You describe the motion you want, and the model figures out the technical details.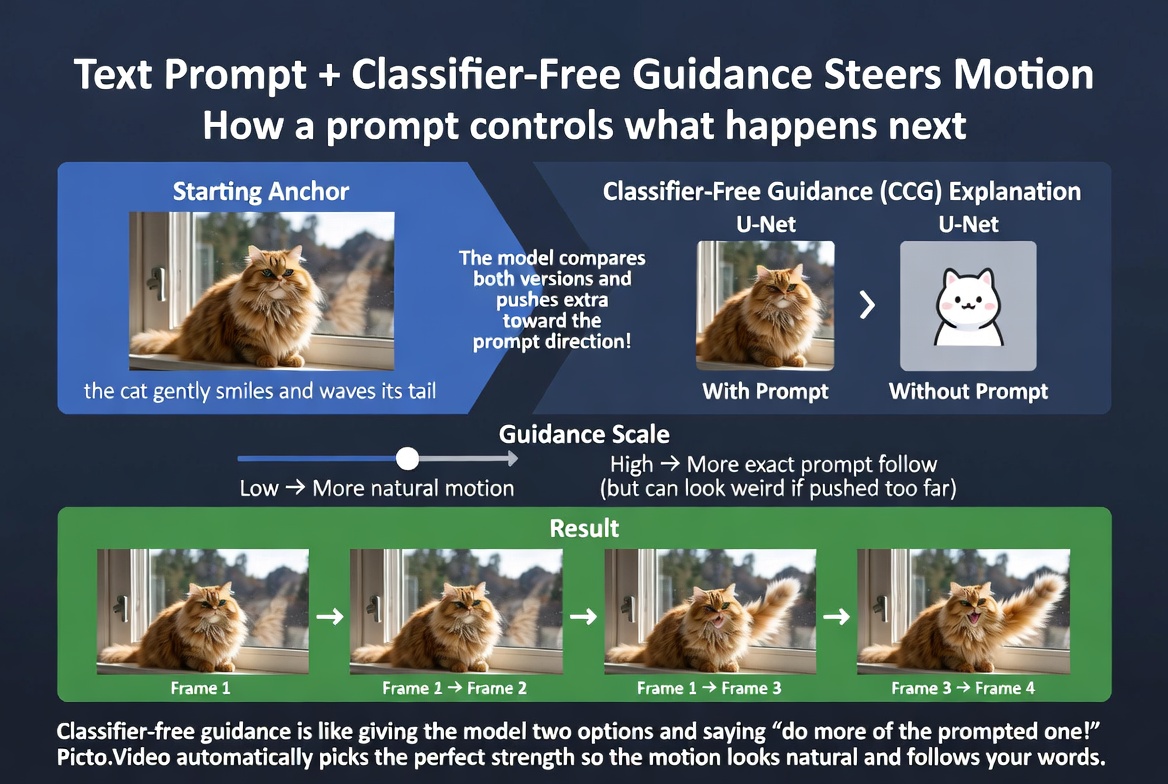 Classifier-free guidance compares prompted and unprompted predictions, then amplifies the difference to steer motion toward your description.
Classifier-free guidance compares prompted and unprompted predictions, then amplifies the difference to steer motion toward your description.
Current Limitations
Why are AI videos so short? Most models generate 3 to 10 seconds of video. The reason is computational. Remember that 3D latent block? It grows with every additional frame. Double the video length and you roughly double the memory and compute required. Temporal attention is especially expensive — every frame attending to every other frame scales quadratically. Going from 24 frames to 240 frames is not a 10x increase in cost; it is closer to 100x.
Why does physics sometimes look wrong? A ball might roll uphill. Water might flow the wrong direction. A person might float slightly off the ground. This happens because the model learned motion by watching millions of videos, not by understanding the laws of physics. It knows what motion looks like statistically, not why it happens. When the statistical pattern is clear — faces turning, hair blowing in wind — the model does well. When the physics is subtle or uncommon in training data, the model guesses, and sometimes it guesses wrong.
Why do complex prompts fail? Asking for "a person walks to the door, picks up a key, then opens the lock" requires the model to understand sequence, causality, and object permanence. These are things that current video diffusion models do not reliably have. They are great at generating a single continuous action but struggle with multi-step sequences where the outcome of one action affects the next.
Why are hands and fingers still difficult? Hands require very precise spatial coordination that must remain consistent across every frame. Even a small error in finger positioning is immediately obvious to the human eye. Combine this with the fact that training data contains enormous variance in hand positions and angles, and you get a problem that is genuinely hard for statistical models. Hands are improving with each generation of models, but they remain a known weak spot.
None of these are bugs. They are fundamental limitations of the current approach. Diffusion models learn statistical patterns from data. When those patterns are strong and consistent, the models excel. When the patterns are complex, rare, or require reasoning the models have not learned, they struggle. Understanding these limits helps you get better results — you work with the model's strengths rather than fighting its weaknesses.
Where the Field Is Heading
Longer videos are coming through hierarchical approaches: generate a sparse set of keyframes first, then fill in the frames between them. This is much cheaper than generating every frame at once and mirrors how traditional animation works.
Better physics is being addressed through physics-aware training losses — rewarding models not just for visual realism but for obeying physical constraints like gravity and conservation of momentum.
Higher resolution is arriving via more efficient network architectures and larger latent spaces that can capture finer detail without blowing up memory requirements.
More control is emerging through richer conditioning signals. Instead of just an image and text, future models will accept depth maps, pose skeletons, and explicit motion trajectories — giving you precise control over how the generated motion unfolds.
But even with all these advances, there is one persistent challenge that defines the quality of AI video: temporal consistency. Why do some AI videos look subtly "off" even when every individual frame looks great? How are models getting better at fixing this? In the next article, we will dive deep into the science of temporal consistency and why it is the frontier of video generation quality.
Picto.Video uses image-to-video models like these to animate your photos.
See it in action