Introduction
You've probably seen it - an AI-generated video where a person's face subtly morphs between frames, or a background element flickers in and out of existence. Maybe a ring on someone's finger appears and vanishes. Or the texture of a wall shimmers like it can't make up its mind what material it's made of.
These aren't random glitches. They're symptoms of a specific technical challenge called temporal consistency - arguably the hardest problem in AI video generation today.
Over the previous three articles in this series, we've built up a picture of how AI video generation works. We know how diffusion models learn to remove noise to create images. We know how latent space makes this computationally practical. And we know how image-to-video models extend diffusion into the time dimension. This article is about the hardest part of that process: making all those frames agree with each other.
Temporal consistency, in plain terms, means ensuring that objects, faces, textures, and scenes look the same across every frame of a video. A person's nose shouldn't change width between frame 10 and frame 11. The color of a shirt shouldn't drift from blue to purple over the course of three seconds. Gravity should apply consistently. It sounds obvious - our brains enforce these rules effortlessly when we watch real video - but for a generative model, it's an enormous challenge.
What Goes Wrong: A Catalog of Artifacts
Before we talk about solutions, let's be specific about the problems. AI video artifacts fall into a few recognizable categories, and understanding them helps explain why they happen.
Face morphing is the most immediately noticeable. A person's face subtly changes shape between frames - the nose gets slightly wider, the eyes shift position by a pixel or two, the jawline softens and then sharpens. Each individual frame might look perfectly fine. But when played in sequence, the face appears to breathe and ripple in an unsettling way. We're extraordinarily sensitive to this because our brains have specialized circuitry for face recognition.
Flickering textures show up as surfaces that shimmer or change pattern from frame to frame. A brick wall might subtly rearrange its mortar lines. Fabric weave might shift direction. Skin texture might alternate between smooth and rough. It looks like the surface is alive.
Object identity loss is when small details can't maintain their existence across frames. A ring on a finger appears and disappears. Hair changes length from one frame to the next. A button on a shirt blinks in and out. The model doesn't have a persistent inventory of objects - it's reconstructing the scene fresh each frame, and small details sometimes get dropped or added.
Background drift is subtler: the background slowly slides, warps, or shifts perspective over the course of the video, even though the camera should be stationary. It's as if the scenery behind the subject is gently swimming.
Physics violations round out the catalog. Objects float when they should fall. Shadows move independently from the objects casting them. Liquid flows upward. Hair defies gravity in ways that feel wrong even if you can't articulate the specific rule being broken.
Why does all of this happen? Because the model is making semi-independent decisions for each frame, and small inconsistencies compound over time. It's like the telephone game - each frame is whispering to the next, and details get lost in translation.
Why Independent Frame Generation Fails
To understand why temporal consistency is so hard, imagine this thought experiment. You want to create a 24-frame video of a person smiling. You hire 24 artists, put each one in a separate room, and give them all the same brief: "Paint frame N of a person smiling. Here's a reference photo."
Each artist knows roughly what the scene should look like. They're all talented. They all have the same reference. But they can't see each other's work. They don't coordinate on the details - how wide the smile is at this exact moment, the precise angle of the head, where exactly each strand of hair falls.
The result: 24 individually beautiful paintings that, when played in sequence, jitter and jump. The smile is slightly different in every frame. The head angle varies by a degree or two. Hair rearranges itself randomly. Each frame is fine in isolation. The sequence is unwatchable.
This is essentially what happens when you try to generate video frames without temporal connections between them. Even with the same input prompt, the same conditioning image, and similar noise patterns, there's inherent randomness in the generation process. The diffusion model is sampling from a probability distribution, and each sample is slightly different.
With still images, that randomness is a feature - it's what lets you generate diverse outputs from the same prompt. With video, that same randomness becomes the enemy. You don't want diversity between frames. You want agreement. You want every frame to commit to the same version of reality.
The fundamental tension is clear: the model needs enough freedom to generate realistic detail, but enough constraint to keep that detail consistent across time. Too much freedom and you get jitter. Too much constraint and you get frozen, lifeless output. Every video generation model is navigating this tradeoff. Without temporal connections, each frame is generated independently and details vary randomly. With connections, all frames agree on identity, lighting, and physics.
Without temporal connections, each frame is generated independently and details vary randomly. With connections, all frames agree on identity, lighting, and physics.
Temporal Attention: How Models Maintain Consistency
As we covered in the previous article, temporal attention is the key mechanism that lets video generation models maintain consistency across frames. But let's go deeper into how this actually works, because the details matter.
At each step of the denoising process, the model processes each frame through its neural network. In a standard image diffusion model, the network uses spatial attention - each region of the image attends to other regions within the same frame, allowing the model to understand relationships like "this shadow belongs to that object" or "this eye is part of the same face as that nose."
Temporal attention adds another dimension. After processing spatial relationships within each frame, the model asks a new question: "What do the surrounding frames look like at this same spatial position?" Frame 5 looks at what's happening at position (x, y) in frames 4 and 6. If those frames show a blue eye at that position, frame 5 is strongly encouraged to also show a blue eye there.
This creates a soft constraint - not a hard rule, but a statistical pull toward consistency. The attention mechanism computes similarity scores between corresponding positions across frames and uses those scores to blend information. The stronger the similarity, the more influence neighboring frames have.
The attention is bidirectional. Frame 5 looks at both frame 4 and frame 6 during generation. This matters because it means information flows in both directions through time, not just forward. Frame 12 can influence frame 10, and frame 10 can influence frame 12. The result is a chain of consistency that propagates through the entire video.
But the chain has limits. Frame 1 and frame 24 are connected only through many intermediate frames, and information gets diluted at each link. This is why longer videos show more temporal drift - the first frame and the last frame can look subtly different because the consistency signal has been diluted through 23 intermediate hops. It's like a line of people playing telephone: the message stays accurate between adjacent people, but errors accumulate over distance.
Some models address this with global temporal attention, where every frame can attend to every other frame simultaneously. This creates much stronger consistency - frame 1 can directly constrain frame 24 without going through intermediaries - but it's computationally expensive. The memory and compute costs scale quadratically with the number of frames. For short videos (16-24 frames), this is manageable. For longer sequences, it quickly becomes prohibitive, which is one reason why AI-generated videos are still typically short.
A good analogy: local temporal attention is like a line of people passing a message, where each person double-checks with the person before and after them to make sure they heard it right. Global attention is like putting everyone in the same room where they can all hear each other. The room approach is better for accuracy, but it gets noisy and expensive with too many people.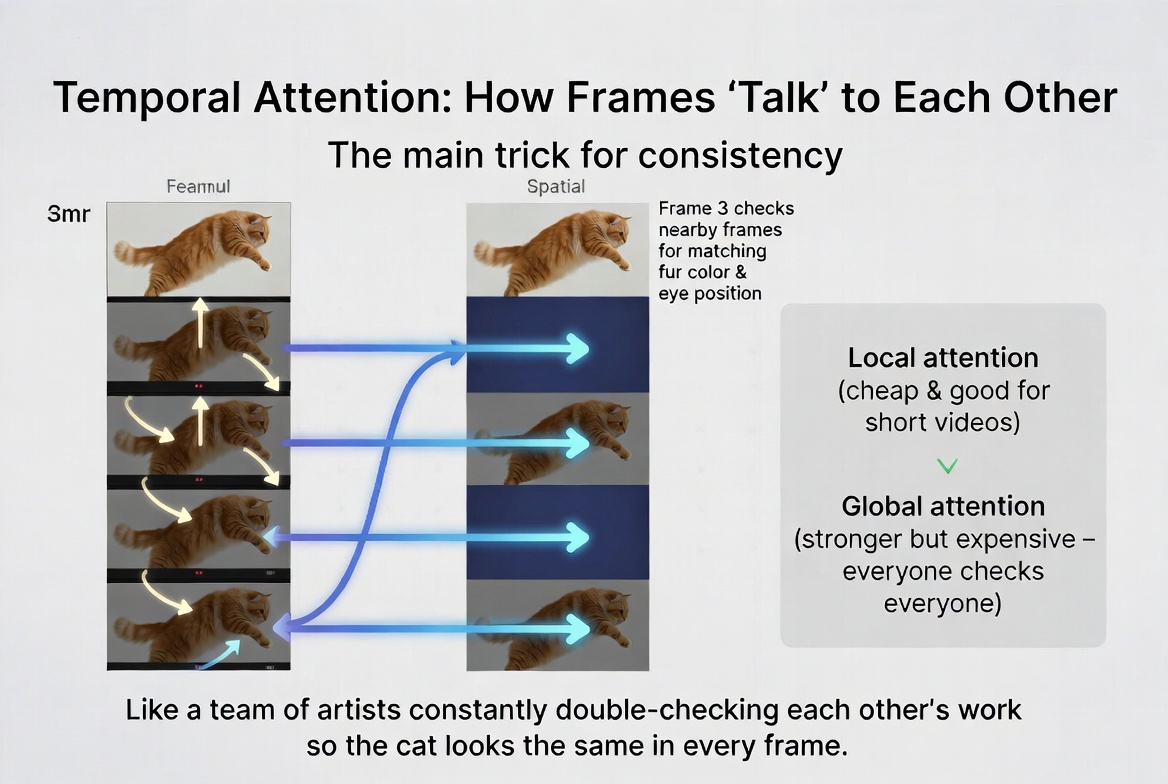 Temporal attention lets each frame reference its neighbors for consistency - like a team of artists constantly double-checking each other's work.
Temporal attention lets each frame reference its neighbors for consistency - like a team of artists constantly double-checking each other's work.
Motion Priors: What Real Movement Looks Like
Temporal attention provides local consistency - it keeps neighboring frames looking similar. But consistency alone isn't enough. The model also needs to understand what realistic motion looks like. A consistent video where nothing moves isn't very useful. And a video with consistent frames but physically impossible motion looks just as wrong as one with flickering textures.
This understanding comes from training data. Video generation models are trained on millions of real video clips - people talking, walking, smiling; wind blowing through trees; water flowing; cars driving. From this enormous corpus, the model learns motion priors: statistical patterns about how things typically move in the real world.
These priors encode a surprisingly detailed understanding of physics and biology. The model learns that faces rotate on specific axes - you can turn your head left and right, tilt it, nod, but you can't rotate it like a wheel. It learns that hair sways with a specific kind of pendulum motion influenced by gravity. It learns that fabric folds follow gravitational pull and that wrinkles form in predictable patterns when an arm bends.
Crucially, these motion priors are implicit. They're baked into the billions of weights in the neural network, not coded as explicit physical rules. The model doesn't have a physics engine. It doesn't know about gravity as a concept. It has simply observed so many examples of things falling that the statistical pattern "unsupported objects accelerate downward" is encoded in its parameters. It's pattern recognition, not simulation.
This works remarkably well for common motions. A gentle smile, a slight head turn, hair blowing in a breeze, a wave of the hand - these are well-represented in the training data, and the model generates them convincingly. The more examples it has seen of a particular motion, the more confidently and accurately it can reproduce it.
But it fails for unusual motions or complex physical interactions, precisely because the model hasn't seen enough examples to learn the pattern. Zero-gravity movement, complex fluid dynamics, multiple objects colliding - these either appear infrequently in training data or involve interactions too complex for the model to capture with its current capacity. The result is motion that looks vaguely plausible for a frame or two but quickly drifts into physical impossibility.
Think of it like a cartoonist who has studied thousands of hours of reference footage. They can draw realistic running, walking, jumping, and dancing from memory. But ask them to animate a complex gymnastics routine or a zero-gravity dance, and they'll have to guess - and their guesses will be informed by what they've seen before, which may not be applicable. Motion priors learned from millions of real videos give the model built-in physics knowledge. Common motions like walking and swaying are reproduced convincingly.
Motion priors learned from millions of real videos give the model built-in physics knowledge. Common motions like walking and swaying are reproduced convincingly.
The Identity Preservation Problem
Of all the consistency challenges in AI video generation, face identity preservation is the most noticeable to humans - and the most demanding to solve.
The reason is biological. We have evolved extraordinarily sensitive facial recognition capabilities. Research suggests we can detect changes as small as 1-2% in the spacing between facial features. A nose that's two pixels wider in one frame compared to the next? We notice. A jawline that's slightly softer? We notice. The exact same shift in a background texture would be completely invisible to us, but on a face, it triggers an immediate "something is wrong" response.
The model, unfortunately, doesn't have a concept of "identity." It doesn't know that the face in frame 10 and the face in frame 11 are supposed to be the same person. It only knows statistical patterns: "at this position in this frame, given the surrounding context and the input conditioning, there should be a face that looks roughly like this." The problem is that "roughly like this" operates at a coarser resolution than our perceptual sensitivity demands.
Think of it this way. The model's internal representation of a face might capture overall shape, skin tone, approximate eye color, general proportions. But the fine-grained details - the exact curvature of the upper lip, the precise distance between the inner corners of the eyes, the specific angle of the nose bridge - these are represented with less precision. Each frame samples from a probability distribution around the "right" answer, and even small sampling variations produce noticeable identity shifts.
Several approaches are being explored to address this. Face-specific encoders create stronger identity constraints by extracting a detailed face embedding from the input image and feeding it to the model at every frame. Reference attention works by periodically re-attending to the original input image during generation, essentially saying "remember, this is what the person actually looks like." And post-processing methods run a separate face consistency model after generation to detect and fix subtle identity shifts.
This is one of the most active areas of research in video generation, and it's a key differentiator between competing models. The models that nail face consistency feel dramatically more real than those that don't, even if their overall visual quality is comparable. Face identity preservation is the hardest consistency challenge - we notice even 1-2 pixel shifts in facial features. Techniques like face encoders and reference attention help keep faces stable.
Face identity preservation is the hardest consistency challenge - we notice even 1-2 pixel shifts in facial features. Techniques like face encoders and reference attention help keep faces stable.
Practical Tips: Working With (Not Against) the Model
Understanding how temporal consistency works (and fails) gives you practical strategies for getting better results from image-to-video tools.
Simpler prompts work better. "Gentle smile" produces more consistent results than "person turns around while waving and talking." Every additional motion you request is another source of potential inconsistency. Let the model do one thing well rather than three things poorly.
Front-facing portraits are the sweet spot. The model has seen more front-facing training data than any other angle, so identity preservation is strongest for this composition. Profile views and unusual angles have fewer training examples to draw from, which means more uncertainty and more drift.
Subtle motion is your friend. A slight smile, a gentle head tilt, a slow blink - these small movements play to the model's strengths. Large movements like full-body dancing or dramatic head turns push the model into territory where its motion priors are less reliable and consistency is harder to maintain.
Good input photos matter more than you might think. A clear, well-lit photo with a visible face gives the model substantially more information to anchor to. Blurry, low-resolution, or partially occluded faces force the model to guess at details, and those guesses will vary between frames.
Shorter is better. Consistency degrades over time due to the drift problem we discussed. A 3-second video will almost always look more consistent than a 10-second one. This is why tools like picto.video are designed around short, focused animations - it plays to the model's strengths rather than fighting its limitations. By staying short and subtle, you avoid drift and play to the model's strengths - resulting in natural, consistent videos.
By staying short and subtle, you avoid drift and play to the model's strengths - resulting in natural, consistent videos.
Where This Is Heading
The trajectory of temporal consistency research is clear: it's getting better fast. The artifacts that were common six months ago are noticeably rarer today, and the pace of improvement is accelerating.
Several promising approaches are being explored. Physics-aware training aims to teach models not just what motion looks like, but the rules that govern it - encoding basic physics principles so the model doesn't just pattern-match but actually understands that unsupported objects fall and shadows track their light source.
Hierarchical generation takes a different approach: generate a handful of keyframes first with strong global consistency, then fill in the intermediate frames. This ensures the overall trajectory is coherent before worrying about frame-to-frame smoothness.
Test-time optimization adds additional consistency checks during the generation process itself, rather than relying solely on what the model learned during training. The model generates a batch of frames, evaluates their consistency, and adjusts before finalizing.
And longer context windows - processing more frames simultaneously - directly attack the drift problem by strengthening the attention chain between distant frames. As hardware improves and architectures become more memory-efficient, models can maintain strong consistency over longer sequences.
The gap between "AI video" and "real video" in terms of consistency is narrowing faster than most people expect. Within the next few years, temporal consistency will likely be a solved problem for short-form video. The remaining challenges will be about longer videos, complex multi-person scenes, and precise artistic control over motion.
Wrapping Up the Series
This completes our four-part series on how image-to-video AI works. From the noise-removal trick of diffusion to the compression magic of latent space to the temporal architecture of video models to the consistency challenges we covered today - you now understand the core technology behind AI video generation.
It's a field moving remarkably fast, and understanding these fundamentals puts you in a great position to evaluate and use these tools as they continue to evolve. The next time you see an AI-generated video with a subtle face morph or a flickering texture, you'll know exactly why it happened - and you'll have a sense of how close the field is to fixing it.
Read the full series